Naive Bayes Decoding
I am applying for a job as a Principal Data Scientist at AstraZeneca. I analyzed a data set from FDA on adverse effects associated with medications. Here's the project I built in a week https://github.com/mariakesa/AstraZenecaAssignment In the project I used a Naive Bayes model on word counts of medications and complications. The assignment says that you have to be able to explain what you did in your analyses and since I'm practicing for an interview, I thought it would be fun to explain the algorithm here and apply it to some data from the visual cortex.
I downloaded data from the visual cortex while the mice were viewing natural images (either 32 images for some experiments repeated 96 times) https://figshare.com/articles/Recording_of_19_000_neurons_across_mouse_visual_cortex_during_sparse_noise_stimuli/9505250 . The data comes from a calcium imaging experiment with 11,000 neurons. The activations are deconvolved fluorescence tracings. We specify the class of the sample with the index of the image.
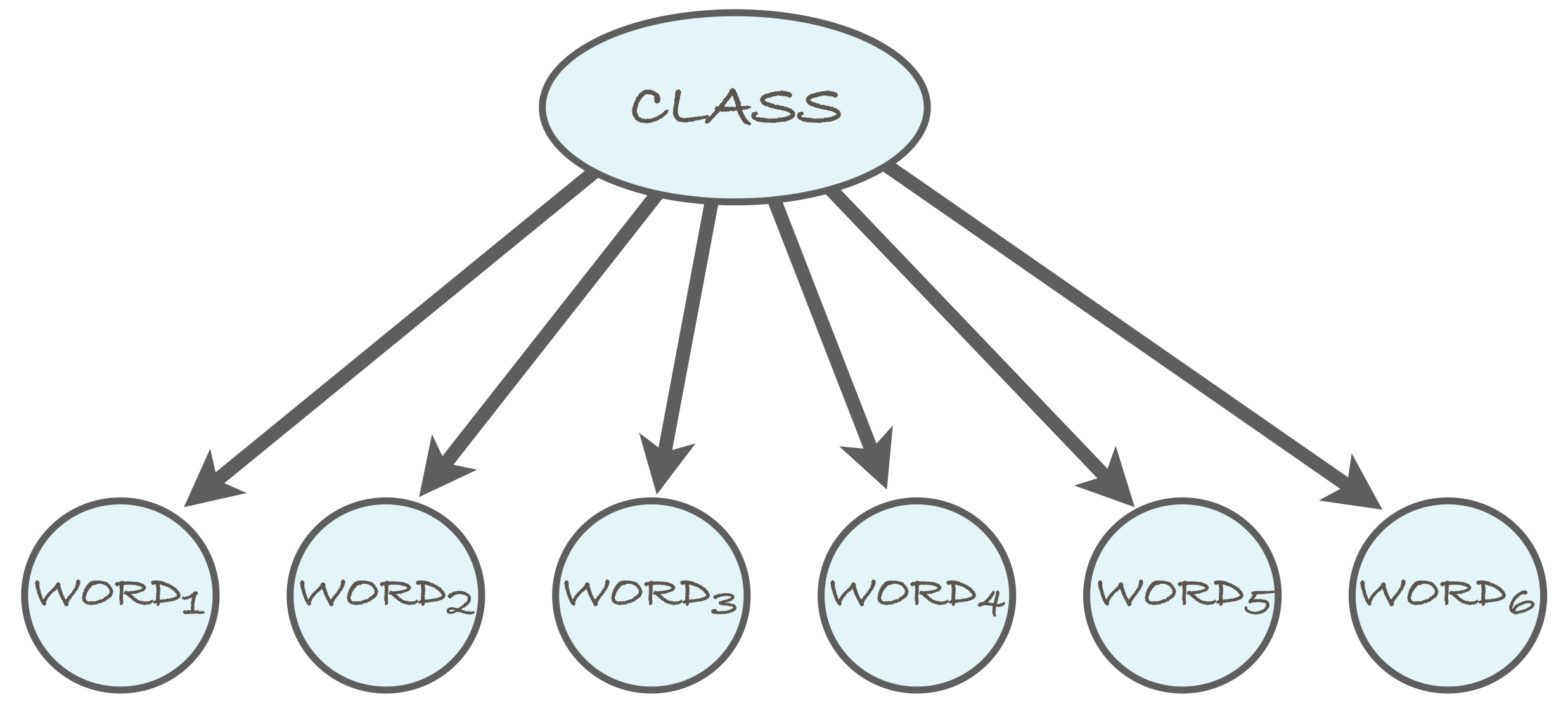
Naive Bayes is a supervised probabilistic model where the features, e.g. deconvolved neural activations in our case or words in the case of text are conditionally independent given the class (in our case the stimulus). A simple use case for the algorithm is spam filtering. Spam messages have a different distribution of words than real messages. These differences in word occurrence can be exploited for accurate classification. Naive Bayes is a simple model due to the very strong independence assumptions that it makes. Remember, if two variables are independent, they are uncorrelated, but the reverse is not true. In effect, it states that neurons are independent given the stimulus. This means that the observed correlations between neurons are solely due to the common stimulus in the Naive Bayes model.
How well does the Naive Bayes decoder perform on the V1 data set? With a 33% test set, the accuracy of the classifier is 99.75% https://github.com/mariakesa/Neural-Data-Analysis/blob/master/NaiveBayesDecoding.ipynb
You can use the clf.feature_log_prob_ from sklearn to see the multinomial probabilities that is associated with each neuron according to the stimulus.
You can then take the correlations between log probabilities between the different stimuli. Here's a heatmap of that correlation matrix.

I think these points display a principle. It is difficult to see patterns in these plots. Yet the decoding accuracy is a meaningful construct that can be used for reasoning about the data. I think it helps to reason on constructs that express particular assumptions and theorize at the level of models and their API's instead of raw data which just looks like a configuration of pebbles at a beach.
\
I downloaded data from the visual cortex while the mice were viewing natural images (either 32 images for some experiments repeated 96 times) https://figshare.com/articles/Recording_of_19_000_neurons_across_mouse_visual_cortex_during_sparse_noise_stimuli/9505250 . The data comes from a calcium imaging experiment with 11,000 neurons. The activations are deconvolved fluorescence tracings. We specify the class of the sample with the index of the image.
Naive Bayes is a supervised probabilistic model where the features, e.g. deconvolved neural activations in our case or words in the case of text are conditionally independent given the class (in our case the stimulus). A simple use case for the algorithm is spam filtering. Spam messages have a different distribution of words than real messages. These differences in word occurrence can be exploited for accurate classification. Naive Bayes is a simple model due to the very strong independence assumptions that it makes. Remember, if two variables are independent, they are uncorrelated, but the reverse is not true. In effect, it states that neurons are independent given the stimulus. This means that the observed correlations between neurons are solely due to the common stimulus in the Naive Bayes model.
How well does the Naive Bayes decoder perform on the V1 data set? With a 33% test set, the accuracy of the classifier is 99.75% https://github.com/mariakesa/Neural-Data-Analysis/blob/master/NaiveBayesDecoding.ipynb
You can use the clf.feature_log_prob_ from sklearn to see the multinomial probabilities that is associated with each neuron according to the stimulus.
You can then take the correlations between log probabilities between the different stimuli. Here's a heatmap of that correlation matrix.
I think these points display a principle. It is difficult to see patterns in these plots. Yet the decoding accuracy is a meaningful construct that can be used for reasoning about the data. I think it helps to reason on constructs that express particular assumptions and theorize at the level of models and their API's instead of raw data which just looks like a configuration of pebbles at a beach.
\
Kommentaarid
Postita kommentaar